
A common problem that occurs when working with Web Services is how-to maintaining changes to the WSDL and/or XSD files that are used by the service. The problem occurs when performing changes to the WSDL (or XSD) files like removing operations, renaming operations, changing the structure of data types etc. As you might always not be aware of which clients that are using your service(s); you want to make sure that they continues to work even after you have implemented changes to your service. As support for dealing with this has not been built into the Web services architecture / standards; it is basically left to each implementer to deal with this problem.
One way of dealing with this problem is to use Namespaces versions. The approach for this is as:
1. Use different XML namespaces for different version of the service.
2. Send a specific namespace value along with every SOAP message and result.
3. Based on this value a Web Service implementation (mediator) can then correctly determine what to do with the incoming message.
You first need to ensure that the namespace for the XML elements resulting from that document is unique, for example, suppose that you now are using a namespace like:
targetNamespace="http://example.com/mySchema.xsd".
You then need to change this to:
targetNamespace="http://example.com/2007/11/01/mySchema.xsd"
Where the numbers are year, month and date (it is not likely that you will alter the namespace more than once a day...).
Now each request will be accompanied with a reference to a namespace thus leaving it up to the Web Services to deal with what to do with requests that come in for any particular namespace.
Next thing is to decide what to do with the various types of incoming requests. One approach here is to generate an error if a request for an older namespace is received, and leave it up to the client to deal with this. Another approach is to use a mediator, as mentioned earlier in the post. The task of the mediator is to determine what to do with Web service requests that come in for any particular namespace. This is done by examination of the date stamp on the namespace (introduced in the previous steps) and then route requests from the older namespace to the older version of the Web service, while routing requests from the newer namespace to the new version of the Web service. This means that the URL to the Web Service (the mediator) will always be the same to your external clients, while you are routing it to different services internally.
As a mediator you could either use a Web Service that you write the code yourself for to handle this, or you could look into using our ESB (Enterprise Service Bus) product for this task.
onsdag, december 05, 2007
tisdag, november 27, 2007
Building a Web Service from a XSD using JDeveloper 11
A few days ago I wrote a post about building a Web Service from a XSD using JDeveloper 10.1.3.3. As a result of this I got a mail from Gerard Davison who informed me that this will be even easier in JDeveloper 11 using the WSDL editor and the top down generator:
Thanks a lot for the information Gerard!
It also turns out that we are having a demo for this on OTN, check the one under 'WSDL Editor New Features'.
- Create a new WSDL
- Put the XSD somewhere nearby in the project
- Tile the editors
- Pick up the country info element and drop in the empty "PortType" column. The tool will prompt you for the name of the portType, and generate a single operation that takes this types as the input and output message.
- Pick up and drop the portType on the binding, then the new binding on the services column. You should now have a valid WSDL
- Now use the generate Java web service from WSDL wizard.
Thanks a lot for the information Gerard!
It also turns out that we are having a demo for this on OTN, check the one under 'WSDL Editor New Features'.
fredag, november 23, 2007
Some Notes on the XX:AppendRatio JVM Parameter
If you install the Oracle Application Server 10.1.3.1+ you will see that the JVM parameter -XX:AppendRatio=3 is set for the OC4J instance by default, however there is not much describing it in the documentation, and it might not be exactly clear from its name what it is used for.
The only entry in the Oracle documentation is found in the Oracle Application Server Performance Guide 10g Release 3 (10.1.3.1.0), Chapter 3 - Top Performance Areas where we say that:
"With the Sun 5.0 JVM, under some circumstances under heavy load, synchronization in an application can result in thread starvation. This may cause some requests for an application to appear hung or to timeout after a long time.
In 10g Release 3 (10.1.3.1.0) the parameter: -XX:AppendRatio=3 is specified by default for managed OC4J. For standalone OC4J, if you believe your installation has this problem, we recommend setting the JDK parameter: -XX:AppendRatio=3 to avoid this problem."
There is also a reference to the Sun JVM Bug Database entry 4985566 that describes the details of the problem.
However, there is a better description of the problem and the purpose in the Sun JVM Bug Database entry 6383015.
Here the purpose of the parameter is described as: "The VM option -XX:AppendRatio=N can be used to control how often an append is done rather than an append. If set to 0 then every enqueue will be an append and the observed behaviour will be 'fair' if desiring FIFO like ordering."
It then continues a bit down with: "In 1.5.0 the monitor queuing policy is 'mostly prepend', which is essentially LIFO except that every N queue additions are done as an append rather than a prepend. Prepending yields better throughput/performance by trying to allow the most recently blocked thread to run next in the expectation that it will still have a warm cache etc."
So, with this is mind we can go to the following conclusions:
So, I hope this have given you a better understanding of what the XX:AppendRatio JVM Parameter does and why it is set by default when installing the Oracle Application Server 10.1.3.1+.
The only entry in the Oracle documentation is found in the Oracle Application Server Performance Guide 10g Release 3 (10.1.3.1.0), Chapter 3 - Top Performance Areas where we say that:
"With the Sun 5.0 JVM, under some circumstances under heavy load, synchronization in an application can result in thread starvation. This may cause some requests for an application to appear hung or to timeout after a long time.
In 10g Release 3 (10.1.3.1.0) the parameter: -XX:AppendRatio=3 is specified by default for managed OC4J. For standalone OC4J, if you believe your installation has this problem, we recommend setting the JDK parameter: -XX:AppendRatio=3 to avoid this problem."
There is also a reference to the Sun JVM Bug Database entry 4985566 that describes the details of the problem.
However, there is a better description of the problem and the purpose in the Sun JVM Bug Database entry 6383015.
Here the purpose of the parameter is described as: "The VM option -XX:AppendRatio=N can be used to control how often an append is done rather than an append. If set to 0 then every enqueue will be an append and the observed behaviour will be 'fair' if desiring FIFO like ordering."
It then continues a bit down with: "In 1.5.0 the monitor queuing policy is 'mostly prepend', which is essentially LIFO except that every N queue additions are done as an append rather than a prepend. Prepending yields better throughput/performance by trying to allow the most recently blocked thread to run next in the expectation that it will still have a warm cache etc."
So, with this is mind we can go to the following conclusions:
- If the XX:AppendRatio parameter is unset in JDK 1.5 then the monitor queuing policy will be LIFO. This might cause some threads to be treated unfair, and lead to starvation.
- If the XX:AppendRatio parameter is set to 0 then the monitor queuing policy will be almost like FIFO, however 100% FIFO is not guaranteed as described in bug 4985566 above.
- If the XX:AppendRatio parameter is set to 3 then each 3:rd queue addition is done as an append rather than a prepend. This will take some advantage of the performance benefits using LIFO, but it will better ensure fairness trying to prevent thread starvation.
So, I hope this have given you a better understanding of what the XX:AppendRatio JVM Parameter does and why it is set by default when installing the Oracle Application Server 10.1.3.1+.
torsdag, november 22, 2007
Building a Web Service from a XSD using JDeveloper
Yesterday I was asked how to create a Web Service from a XSD file using JDeveloper by a colleague, so I thought I'd might share the answer I gave to a wider audience. Hopefully someone else out there might also have some use for it.
The purpose of this example is to show how you can build a Java Web Service starting with only a single XSD file using JDeveloper.
1. Create an empty project in JDeveloper (I used version 10.1.3.3).
2. Add the XSD to your project, in this example I use an XSD that looks like:
<schema xmlns="http://www.w3.org/2001/XMLSchema"
targetNamespace="http://www.oracle.com/pcbpel/CountryInfo"
elementFormDefault="qualified">
<element name="CountryInfo">
<complexType>
<sequence>
<element name="Country" maxOccurs="unbounded">
<complexType>
<sequence>
<element name="Name" type="string"/>
<element name="Capital" type="string"/>
<element name="Area" type="decimal"/>
</sequence>
</complexType>
</element>
</sequence>
</complexType>
</element>
</schema>
3. Select the XSD in the Applications Navigator
4. Select Tools -> JAXB Compilation from the Menu
5. Now you have JAXB generated Java classes based on your XSD in your project. This is described more in:
http://www.oracle.com/webapps/online-help/jdeveloper/10.1.3?navId=4&navSetId=_&vtTopicFile=working_with_xml/xml_pjaxb.html
6. Create a new Java class, this is the class that will be the Web Service
7. In this class create a method (this will be exposed as a Web Service method) it has a javax.xml.soap.SOAPElement as input parameter and void as return value, like:
public void testMethod(javax.xml.soap.SOAPElement myDoc)
8. In the method body, add code to unmarshal the document and in this example just write it to System.out:
try {
JAXBContext jc = JAXBContext.newInstance("project3");
Unmarshaller u = jc.createUnmarshaller();
CountryInfo countryInfo = (CountryInfo)u.unmarshal(myDoc);
List lst = countryInfo.getCountry();
for(Iterator iter = lst.iterator(); iter.hasNext();) {
CountryInfo.CountryType country = (CountryInfo.CountryType)iter.next();
System.out.println( country.getName() + ", " + country.getCapital());
}
}
catch (JAXBException je) { je.printStackTrace(); }
9. Start the Java Web Service wizard from the New Gallery, select the newly generated class and just use the default values in the Wizard, except for SOAP Format, here use Document/Literal.
10. Before deploying the Web Service, make sure that all needed files are included in the deployment profile.
11. Once done, either deploy the Web Service to an Application Server or standalone OC4J instance and test it using XML like:
<?xml version="1.0" encoding="UTF-8" ?>
<CountryInfo xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.oracle.com/pcbpel/CountryInfo src/xsd/CountryInfo.xsd"
xmlns="http://www.oracle.com/pcbpel/CountryInfo">
<Country>
<Name>Sweden</Name>
<Capital>Stockholm</Capital>
<Area>1.0</Area>
</Country>
</CountryInfo>
this should give the following printed to System.out:
07/11/22 12:29:31 Sweden, Stockholm
The purpose of this example is to show how you can build a Java Web Service starting with only a single XSD file using JDeveloper.
1. Create an empty project in JDeveloper (I used version 10.1.3.3).
2. Add the XSD to your project, in this example I use an XSD that looks like:
<schema xmlns="http://www.w3.org/2001/XMLSchema"
targetNamespace="http://www.oracle.com/pcbpel/CountryInfo"
elementFormDefault="qualified">
<element name="CountryInfo">
<complexType>
<sequence>
<element name="Country" maxOccurs="unbounded">
<complexType>
<sequence>
<element name="Name" type="string"/>
<element name="Capital" type="string"/>
<element name="Area" type="decimal"/>
</sequence>
</complexType>
</element>
</sequence>
</complexType>
</element>
</schema>
3. Select the XSD in the Applications Navigator
4. Select Tools -> JAXB Compilation from the Menu
5. Now you have JAXB generated Java classes based on your XSD in your project. This is described more in:
http://www.oracle.com/webapps/online-help/jdeveloper/10.1.3?navId=4&navSetId=_&vtTopicFile=working_with_xml/xml_pjaxb.html
6. Create a new Java class, this is the class that will be the Web Service
7. In this class create a method (this will be exposed as a Web Service method) it has a javax.xml.soap.SOAPElement as input parameter and void as return value, like:
public void testMethod(javax.xml.soap.SOAPElement myDoc)
8. In the method body, add code to unmarshal the document and in this example just write it to System.out:
try {
JAXBContext jc = JAXBContext.newInstance("project3");
Unmarshaller u = jc.createUnmarshaller();
CountryInfo countryInfo = (CountryInfo)u.unmarshal(myDoc);
List lst = countryInfo.getCountry();
for(Iterator iter = lst.iterator(); iter.hasNext();) {
CountryInfo.CountryType country = (CountryInfo.CountryType)iter.next();
System.out.println( country.getName() + ", " + country.getCapital());
}
}
catch (JAXBException je) { je.printStackTrace(); }
9. Start the Java Web Service wizard from the New Gallery, select the newly generated class and just use the default values in the Wizard, except for SOAP Format, here use Document/Literal.
10. Before deploying the Web Service, make sure that all needed files are included in the deployment profile.
11. Once done, either deploy the Web Service to an Application Server or standalone OC4J instance and test it using XML like:
<?xml version="1.0" encoding="UTF-8" ?>
<CountryInfo xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.oracle.com/pcbpel/CountryInfo src/xsd/CountryInfo.xsd"
xmlns="http://www.oracle.com/pcbpel/CountryInfo">
<Country>
<Name>Sweden</Name>
<Capital>Stockholm</Capital>
<Area>1.0</Area>
</Country>
</CountryInfo>
this should give the following printed to System.out:
07/11/22 12:29:31 Sweden, Stockholm
fredag, november 16, 2007
Don't Forget of the Permanent Generation...
This week I was at a customer where we would install a SOA Suite server and deploy quite a lot of BPEL processes onto it. Most things went fine until the end of the deployment where we encountered a problem: java.lang.OutOfMemoryException, I was first a bit confused since we had assigned 2Gb of memory to the JVM - so how could that be?
Simple, I forgot about the Permanent Generation Size, and this post is my equivalent of writing it on the black board 100 times in order to remind myself to not forget about it again in the future...
We solved the problem by adding these 2 JVM parameters:
-XX:PermSize=256 -XX:MaxPermSize=256m
So, what do they do?
The permanent generation is allocated outside of the normal heap and holds objects of the VM itself such as class objects and method objects. If you have programs that load many classes (like deployment of many BPEL processes in a batch), you may need a larger permanent generation.
Since the sizing of this is done independently from the other generations, this means that even if you setup a heap of 2Gb, you might still encounter problems in the permanent generation cause if you do not specify this it will fallback on the defaults .
Why are they set to the same value above? Simply because we want to minimize large garbage collection here.
Once we had reconfigured the OC4J instance with these settings the deployment went fine.
Simple, I forgot about the Permanent Generation Size, and this post is my equivalent of writing it on the black board 100 times in order to remind myself to not forget about it again in the future...
We solved the problem by adding these 2 JVM parameters:
-XX:PermSize=256 -XX:MaxPermSize=256m
So, what do they do?
The permanent generation is allocated outside of the normal heap and holds objects of the VM itself such as class objects and method objects. If you have programs that load many classes (like deployment of many BPEL processes in a batch), you may need a larger permanent generation.
Since the sizing of this is done independently from the other generations, this means that even if you setup a heap of 2Gb, you might still encounter problems in the permanent generation cause if you do not specify this it will fallback on the defaults .
Why are they set to the same value above? Simply because we want to minimize large garbage collection here.
Once we had reconfigured the OC4J instance with these settings the deployment went fine.
torsdag, oktober 04, 2007
What is an Oracle SOA Suite 10.1.3.1+ Cluster?
"Cluster - a number of things of the same kind, growing or held together; a bunch: a cluster of grapes.".
This is how a cluster is defined in the dictionary (http://dictionary.reference.com). Not a particularly exact definition, at least not to me. Then, one often hears that a SOA Suite installation runs in a 'cluster'. But what does this actually means? The definition did not give a particularly good definition. Also, as there are several ways to connect instances together to form a cluster it could be good to know exactly which way that is used in each case. There are (at least) four different ways to form a cluster in Oracle SOA Suite 10.1.3.1+ ; these are:
Let's now discuss them more in detail.
ONS Topology
This is a group of Oracle Notification Server (ONS) in a farm configured to run in same topology. Basically; two or more loosely connected Oracle Application Server nodes. You can create this by using either of the 4 methods Dynamic node discovery, Static hubs, Connection via gateways or Manual configuration. You can read more about these methods in:
http://download-uk.oracle.com/docs/cd/B32110_01/web.1013/b28950/topology.htm#CHDCAIFD
I assume that this is the way most people refer to when they are talking about an Oracle SOA Suite cluster.
OC4J Group
This is a management concept, which is a set of OC4J instances that belong to the same group. Groups enable you to perform common configuration, administration, and deployment tasks simultaneously on all OC4J instances in a group. Some people might argue that this is not a cluster, but is certainly "a number of things of the same kind held together", so according to the dictionary it would be a cluster.
Read more about OC4J Groups in:
http://download-uk.oracle.com/docs/cd/B32110_01/web.1013/b28950/topology.htm#BIHGICBJ
BPEL JGroup Config
This clustering concept allows defining a topology for BPEL instances, for example new processes. This concept uses an Active / Passive model (for the concerned process). In case of a server failure, another Oracle BPEL Server running on another server resumes the process from the last dehydration point.
Read more about this in:
http://download-uk.oracle.com/docs/cd/B31017_01/integrate.1013/b28980/clusteringsoa.htm
OC4J Session Replication
This is a way to replicate sessions in state across applications. This can also be referred to as an application cluster and is the same set of applications hosted by two or more OC4J instances. It can be enabled either globally for all applications running within an OC4J instance or on application basis. There are three ways to do this: multicast, peer-to-peer or database replication. Read more about these in:
http://download.oracle.com/docs/cd/B31017_01/web.1013/b28950/cluster.htm
To summarize, there are (at least) 4 different ways of creating an Oracle SOA Suite 10.1.3.1 cluster. These are the methods and also the intended purpose of them:
So, what do you mean when talking about clusters?
This is how a cluster is defined in the dictionary (http://dictionary.reference.com). Not a particularly exact definition, at least not to me. Then, one often hears that a SOA Suite installation runs in a 'cluster'. But what does this actually means? The definition did not give a particularly good definition. Also, as there are several ways to connect instances together to form a cluster it could be good to know exactly which way that is used in each case. There are (at least) four different ways to form a cluster in Oracle SOA Suite 10.1.3.1+ ; these are:
- ONS Topology
- OC4J Group
- BPEL JGroup Config
- OC4J Session Replication
Let's now discuss them more in detail.
ONS Topology
This is a group of Oracle Notification Server (ONS) in a farm configured to run in same topology. Basically; two or more loosely connected Oracle Application Server nodes. You can create this by using either of the 4 methods Dynamic node discovery, Static hubs, Connection via gateways or Manual configuration. You can read more about these methods in:
http://download-uk.oracle.com/docs/cd/B32110_01/web.1013/b28950/topology.htm#CHDCAIFD
I assume that this is the way most people refer to when they are talking about an Oracle SOA Suite cluster.
OC4J Group
This is a management concept, which is a set of OC4J instances that belong to the same group. Groups enable you to perform common configuration, administration, and deployment tasks simultaneously on all OC4J instances in a group. Some people might argue that this is not a cluster, but is certainly "a number of things of the same kind held together", so according to the dictionary it would be a cluster.
Read more about OC4J Groups in:
http://download-uk.oracle.com/docs/cd/B32110_01/web.1013/b28950/topology.htm#BIHGICBJ
BPEL JGroup Config
This clustering concept allows defining a topology for BPEL instances, for example new processes. This concept uses an Active / Passive model (for the concerned process). In case of a server failure, another Oracle BPEL Server running on another server resumes the process from the last dehydration point.
Read more about this in:
http://download-uk.oracle.com/docs/cd/B31017_01/integrate.1013/b28980/clusteringsoa.htm
OC4J Session Replication
This is a way to replicate sessions in state across applications. This can also be referred to as an application cluster and is the same set of applications hosted by two or more OC4J instances. It can be enabled either globally for all applications running within an OC4J instance or on application basis. There are three ways to do this: multicast, peer-to-peer or database replication. Read more about these in:
http://download.oracle.com/docs/cd/B31017_01/web.1013/b28950/cluster.htm
To summarize, there are (at least) 4 different ways of creating an Oracle SOA Suite 10.1.3.1 cluster. These are the methods and also the intended purpose of them:
- ONS Topology: To connect two or more loosely connected Oracle Application Server nodes.
- OC4J Group: To create a group with a set of OC4J instances.
- BPEL JGroup Config: A set of BPEL Servers that shares the same dehydration store and listens on the same JGroup channels.
- OC4J Session Replication: Used to replicate state across an application deployed on two or more OC4J instances.
So, what do you mean when talking about clusters?
måndag, september 17, 2007
Using Berkeley DB Inside Your JDeveloper Project
Sometimes you need a small database within your JDeveloper project, but you don't want to install any of the usual suspects like Oracle Database 10g Express Edition or Oracle Lite. If so, Oracle Berkeley DB is an ideal candidate. It's very easy to get started with it inside JDeveloper; just follow the steps below, and you will be up and running in just 15 minutes. Start by downloading the Oracle Berkeley DB Java Edition from the OTN:
http://www.oracle.com/technology/software/products/berkeley-db/je/index.html
If you want to read more about Oracle Berkeley DB Java Edition, please refer to this URL:
http://www.oracle.com/technology/products/berkeley-db/je/index.html
http://www.oracle.com/technology/software/products/berkeley-db/je/index.html
- Create a new Project in JDeveloper
- Create a new Library in the JDeveloper project that contains the lib/je-3.2.44.jar file from the Berkeley DB distribution.
- Save the Project.
- Create a new folder in the file system under the newly created JDeveloper project named: src/collections/hello
- In the file system, copy the file examples/collections/hello/HelloDatabaseWorld.java from the Berkeley DB distribution and put it into the src/collections/hello folder.
- In JDeveloper, refresh the project. The copied file should now appear in the JDeveloper project under Application Sources.
- Create a new directory under your project directory called tmp. This is were the database will reside. If you want to place the database somewhere else, change the line in the HelloDatabaseWorld.java that says:
String dir = "./tmp"; - Run the project inside JDeveloper, the result should be similar to:
Writing data
Reading data
0 Hello
1 Database
2 World
If you want to read more about Oracle Berkeley DB Java Edition, please refer to this URL:
http://www.oracle.com/technology/products/berkeley-db/je/index.html
fredag, september 14, 2007
Is it Enough with Business Analysts and Developers when Developing a Rule Based Application?
When talking about rule based programming one often hear that it enables business users and developers to work together. The business users can focus on the business rules part and the developers on the code writing part. This sounds good the first times you hear it, but after a while (at least for me) this sounds perhaps a bit too good to be true. Let me tell you why I believe this to be too good to be true.
If we start to look at the role of the developer; he or she should write the underlying code for the application, and not have to focus on the actual business rules that should be implemented in the system, i.e., should a certain threshold be above or below a certain level, and what should the level be? He should just know that based on this and that data that comes from these and those sources some rules should be applied and then this and that should happen. He should not have to care about exactly what the rules are, how many they are, what thresholds that should be set etc. These things should be left to the business analyst.
The business analyst should on the other hand not have to worry about how to get the data etc, he should just work on the business rules and set the right thresholds that should trigger certain things, for example a discount should be applied for certain customers, but not for others. He should just decide which customers the discount should be applied for and when it should be applied.
Now, don't get me wrong here, I firmly believe that this distinction is good, but I do not believe that it is enough, here are some reasons why:
There are further points on my list, but I will stick with these two for the rest of the discussion. This is not just only for our product in this area; this also goes for our competitors.
Normally the rules are stored in a repository, this requires from the end user to be aware of the location, how to open it, how to navigate to right screen, how to alter the rules and/or variables, how to add the syntax for new rules etc. I believe that any business analyst could learn these things, but is this really things that he/she should be focusing his time on? If I would run a business I would rather see them spend time on doing what they to best; not being a part time developer.
I would instead like to see that these things are handled by just a handful of people; I'll call them Business Rules Maintainers. These are the ones who should be working with the deeper maintenance of the rule repository; they could have a Business Analysts background but also needs to be aware of the technical parts of your rule product.
Now, the business analysts still needs to be there, and they need to be able to quickly adapt the rule system to the business, for example, one of you analysts suddenly discovers that a competitor has lowered the levels for being eligible for a discount and you think that this will impact your business if you do not do the same, so the analyst needs to quickly adjust your current discount levels in the system. At this point he should not have to open a full blown rule administration tool for this, he should just have to open a custom GUI in where he could quickly see what the current discount levels are and equally fast alter and save them.
So, to summarize, I believe that when you are designing the system, you should also start to think if your standard rule administration tool is easy enough to use for all your business analysts. If you come to this conclusion, fine. If not, start to think in terms how you could build a custom GUI for your business analysts that they could easy use to quickly tune your business to sudden changes in the environment, and make this GUI as simple as possible to use so that you won't have to turn your analysts into part time programmers. It might not be necessary to incorporate all your rules and threshold variable in this GUI, just the ones that are most critical to your business, and leave the rest to be maintained by the subset of your analysts that are the Business Rules Maintainers.
So to finalize the discussion, I think that when talking about developing and maintaining a rule based system, it is not enough to split the roles into developers and business analysts, I believe that at least one more role is necessary. It could also be that even further roles are necessary, but that is another discussion.
If we start to look at the role of the developer; he or she should write the underlying code for the application, and not have to focus on the actual business rules that should be implemented in the system, i.e., should a certain threshold be above or below a certain level, and what should the level be? He should just know that based on this and that data that comes from these and those sources some rules should be applied and then this and that should happen. He should not have to care about exactly what the rules are, how many they are, what thresholds that should be set etc. These things should be left to the business analyst.
The business analyst should on the other hand not have to worry about how to get the data etc, he should just work on the business rules and set the right thresholds that should trigger certain things, for example a discount should be applied for certain customers, but not for others. He should just decide which customers the discount should be applied for and when it should be applied.
Now, don't get me wrong here, I firmly believe that this distinction is good, but I do not believe that it is enough, here are some reasons why:
- The tools requires the business user to be aware of technical issue that he or should not have to be aware of.
- I have not yet seen a tool that is easy enough for a business user to use.
There are further points on my list, but I will stick with these two for the rest of the discussion. This is not just only for our product in this area; this also goes for our competitors.
Normally the rules are stored in a repository, this requires from the end user to be aware of the location, how to open it, how to navigate to right screen, how to alter the rules and/or variables, how to add the syntax for new rules etc. I believe that any business analyst could learn these things, but is this really things that he/she should be focusing his time on? If I would run a business I would rather see them spend time on doing what they to best; not being a part time developer.
I would instead like to see that these things are handled by just a handful of people; I'll call them Business Rules Maintainers. These are the ones who should be working with the deeper maintenance of the rule repository; they could have a Business Analysts background but also needs to be aware of the technical parts of your rule product.
Now, the business analysts still needs to be there, and they need to be able to quickly adapt the rule system to the business, for example, one of you analysts suddenly discovers that a competitor has lowered the levels for being eligible for a discount and you think that this will impact your business if you do not do the same, so the analyst needs to quickly adjust your current discount levels in the system. At this point he should not have to open a full blown rule administration tool for this, he should just have to open a custom GUI in where he could quickly see what the current discount levels are and equally fast alter and save them.
So, to summarize, I believe that when you are designing the system, you should also start to think if your standard rule administration tool is easy enough to use for all your business analysts. If you come to this conclusion, fine. If not, start to think in terms how you could build a custom GUI for your business analysts that they could easy use to quickly tune your business to sudden changes in the environment, and make this GUI as simple as possible to use so that you won't have to turn your analysts into part time programmers. It might not be necessary to incorporate all your rules and threshold variable in this GUI, just the ones that are most critical to your business, and leave the rest to be maintained by the subset of your analysts that are the Business Rules Maintainers.
So to finalize the discussion, I think that when talking about developing and maintaining a rule based system, it is not enough to split the roles into developers and business analysts, I believe that at least one more role is necessary. It could also be that even further roles are necessary, but that is another discussion.
onsdag, september 12, 2007
Introduction Into Oracle Business Rules and Rule Based Programming
I was asked the other day by a colleague who wanted to get an introduction into Oracle Business Rules if I had some tips & pointers in order to get started, so I thought I'd might put the answer here; perhaps some more people can use it as well.
For a short, but good introduction to what rule based programming is, please check:
http://www.webreference.com/programming/rule/
The article describes short and concise what rule base programming is all about.
OK, so now you know what it is, but how to get started using it? If you are using the Oracle SOA Suite, then you already have a rule engine in place, so why not start using it?
To see a viewlet on how-to use it, go to the Rules section in OTN: http://www.oracle.com/technology/products/ias/business_rules/index.html
It is available under the 'Viewlets and Tutorials' section. After that, it is time to start learning more about it.
If you have a developer's background, I would suggest that you start with the 'Oracle Business Rules Language Reference' (available at: http://download.oracle.com/docs/cd/B32110_01/web.1013/b28964/toc.htm), this will give you a feel for how the Rule language works; after all this is really the foundation. When going through this document, you will of course need the API, it's available here: http://download.oracle.com/docs/cd/B32110_01/web.1013/b28966/toc.htm.
The document contains many small examples that will help you to get started and get familiar with the language. The examples are run using a command line interface that ships with the product. An alternative is to download the RulesTools extension for JDeveloper 10.1.3.x. This will give you the option to execute script files written in the Rules Language directly in JDeveloper, as well as some other stuff that will ease programming in the Rules Language.
Once you are familiar with the Rule language, or if you are coming from a more business oriented background, you should start to have a look into the Oracle Business Rules Rule Author; it is the GUI that is used for creating the rules. The documentation for it is available here: http://download.oracle.com/docs/cd/B32110_01/web.1013/b28965/toc.htm.
In the previous given link to the Rules section on OTN you will find even more demos and tutorials to help you get started with the Oracle Business Rules.
I hope this will help you to take your first steps down the road of Oracle Business Rules and rule based programming. Good luck!
For a short, but good introduction to what rule based programming is, please check:
http://www.webreference.com/programming/rule/
The article describes short and concise what rule base programming is all about.
OK, so now you know what it is, but how to get started using it? If you are using the Oracle SOA Suite, then you already have a rule engine in place, so why not start using it?
To see a viewlet on how-to use it, go to the Rules section in OTN: http://www.oracle.com/technology/products/ias/business_rules/index.html
It is available under the 'Viewlets and Tutorials' section. After that, it is time to start learning more about it.
If you have a developer's background, I would suggest that you start with the 'Oracle Business Rules Language Reference' (available at: http://download.oracle.com/docs/cd/B32110_01/web.1013/b28964/toc.htm), this will give you a feel for how the Rule language works; after all this is really the foundation. When going through this document, you will of course need the API, it's available here: http://download.oracle.com/docs/cd/B32110_01/web.1013/b28966/toc.htm.
The document contains many small examples that will help you to get started and get familiar with the language. The examples are run using a command line interface that ships with the product. An alternative is to download the RulesTools extension for JDeveloper 10.1.3.x. This will give you the option to execute script files written in the Rules Language directly in JDeveloper, as well as some other stuff that will ease programming in the Rules Language.
Once you are familiar with the Rule language, or if you are coming from a more business oriented background, you should start to have a look into the Oracle Business Rules Rule Author; it is the GUI that is used for creating the rules. The documentation for it is available here: http://download.oracle.com/docs/cd/B32110_01/web.1013/b28965/toc.htm.
In the previous given link to the Rules section on OTN you will find even more demos and tutorials to help you get started with the Oracle Business Rules.
I hope this will help you to take your first steps down the road of Oracle Business Rules and rule based programming. Good luck!
onsdag, september 05, 2007
Oracle Lite, JDeveloper and Invalid Oracle URL specifiedError Code 17067
Oracle Lite and me have never been friends, but I think that I now have finally beaten the ghost. The background is that I simply wanted to use the OLite in order to do some testing, instead of having run to run a full DB, I wanted to use OLite. So far so good.
I started to configure a DB connection in JDeveloper towards the OLite, and this part went smooth and without problem. Next, I created a small project in JDeveloper based on TopLink and session facade beans. This went fine as well, JDeveloper nicely created my POJO's based on the tables. Finally I created a JSF page to display the data. All in all, the design process went smooth as silk.
The problems started when running the project on the embedded OC4J. All I got was a little error saying:
Internal Exception: java.sql.SQLException: Invalid Oracle URL specifiedError Code: 17067
I performed a few searches on this, but could not really find any useful information, so it was time to start to dig. My first thought was that this was a class loading issue, and that the error was not really the real error; so I added the olite40.jar to about all places that would be relevant for my JDeveloper installation. It did not help; I still ended up with the same error.
Next thought, perhaps the error message was a bit relevant after all, so I added a data-sources.xml file to my project (and an orion-application.xml) to get better control of the data sources. Further, I added a new data source based on the predefined OLite connection and told the session.xml file to use this connection. I did not yet make any further modifications, the new data source was correctly picked up, but I ended up with the same error.
Here was what the original data source looked like:
<connection-pool name="jdev-connection-pool-LocalSoaSuiteOLitee">
<connection-factory factory-class="oracle.jdbc.pool.OracleDataSource"
user="username" password="password" url="jdbc:polite4@localhost:1531:orabpel"/>
</connection-pool>
<managed-data-source name="jdev-connection-managed-LocalSoaSuiteOLitee"
jndi-name="jdbc/LocalSoaSuiteOLiteeDS" connection-pool-name="jdev-connection-pool-LocalSoaSuiteOLitee"/>
I noticed the small piece: factory-class="oracle.jdbc.pool.OracleDataSource", this looked a bit strange to me, so I tested to change this into: factory-class="oracle.lite.poljdbc.POLJDBCDriver" instead, like:
<connection-pool name="jdev-connection-pool-LocalSoaSuiteOLitee">
<connection-factory factory-class="oracle.lite.poljdbc.POLJDBCDriver"
user="username" password="password" url="jdbc:polite4@localhost:1531:orabpel"/>
</connection-pool>
<managed-data-source name="jdev-connection-managed-LocalSoaSuiteOLitee"
jndi-name="jdbc/LocalSoaSuiteOLiteeDS" connection-pool-name="jdev-connection-pool-LocalSoaSuiteOLitee"/>
Once I restarted the project, it all went fine. So, why this did happen after all? Well, it looks as JDeveloper treats an OLite connection as an Oracle connection, so when it generates the data-sources.xml file for the embedded OC4J instance is sets the factory class to what it would be for an Oracle database. With this mind, I can summarize what I did into these steps:
I started to configure a DB connection in JDeveloper towards the OLite, and this part went smooth and without problem. Next, I created a small project in JDeveloper based on TopLink and session facade beans. This went fine as well, JDeveloper nicely created my POJO's based on the tables. Finally I created a JSF page to display the data. All in all, the design process went smooth as silk.
The problems started when running the project on the embedded OC4J. All I got was a little error saying:
Internal Exception: java.sql.SQLException: Invalid Oracle URL specifiedError Code: 17067
I performed a few searches on this, but could not really find any useful information, so it was time to start to dig. My first thought was that this was a class loading issue, and that the error was not really the real error; so I added the olite40.jar to about all places that would be relevant for my JDeveloper installation. It did not help; I still ended up with the same error.
Next thought, perhaps the error message was a bit relevant after all, so I added a data-sources.xml file to my project (and an orion-application.xml) to get better control of the data sources. Further, I added a new data source based on the predefined OLite connection and told the session.xml file to use this connection. I did not yet make any further modifications, the new data source was correctly picked up, but I ended up with the same error.
Here was what the original data source looked like:
<connection-pool name="jdev-connection-pool-LocalSoaSuiteOLitee">
<connection-factory factory-class="oracle.jdbc.pool.OracleDataSource"
user="username" password="password" url="jdbc:polite4@localhost:1531:orabpel"/>
</connection-pool>
<managed-data-source name="jdev-connection-managed-LocalSoaSuiteOLitee"
jndi-name="jdbc/LocalSoaSuiteOLiteeDS" connection-pool-name="jdev-connection-pool-LocalSoaSuiteOLitee"/>
I noticed the small piece: factory-class="oracle.jdbc.pool.OracleDataSource", this looked a bit strange to me, so I tested to change this into: factory-class="oracle.lite.poljdbc.POLJDBCDriver" instead, like:
<connection-pool name="jdev-connection-pool-LocalSoaSuiteOLitee">
<connection-factory factory-class="oracle.lite.poljdbc.POLJDBCDriver"
user="username" password="password" url="jdbc:polite4@localhost:1531:orabpel"/>
</connection-pool>
<managed-data-source name="jdev-connection-managed-LocalSoaSuiteOLitee"
jndi-name="jdbc/LocalSoaSuiteOLiteeDS" connection-pool-name="jdev-connection-pool-LocalSoaSuiteOLitee"/>
Once I restarted the project, it all went fine. So, why this did happen after all? Well, it looks as JDeveloper treats an OLite connection as an Oracle connection, so when it generates the data-sources.xml file for the embedded OC4J instance is sets the factory class to what it would be for an Oracle database. With this mind, I can summarize what I did into these steps:
- Add a data-sources.xml file and an orion-application.xml file to the project.
- Create a new data source.
- Change the factory-class to oracle.lite.poljdbc.POLJDBCDriver.
tisdag, september 04, 2007
A Small Comment on MySQL in JDeveloper 11 (Preview Release)
Today I've been doing some tests using MySQL together with the JDeveloper 11 Preview Release. This worked fine, most of the info is covered in the Help chapter, "Working with Non-Oracle Database". However, I missed out one small piece; how to get it to work together with the Embedded OC4J, or rather, where to put the MySQL JDBC JAR file? This as I got an
"Exception: oracle.oc4j.sql.config.DataSourceConfigException: Unable to create : com.mysql.jdbc.Driver"
when trying to run my application.
As of JDeveloper 11, a new default directory structure for user-specific content in JDeveloper for Windows is used. The default location for the system subdirectory is now %APPDATA%\JDeveloper\systemXX.XX.XX.XX, where:
So, in my case, the MySQL JDBC JAR file (mysql-connector-java-3.1.12-bin.jar) should go into the directory:
C:\Documents and Settings\\Application Data\JDeveloper\system11.1.1.0.17.45.24\o.j2ee\embedded-oc4j\applib
Once I put it there, and restarted the embedded OC4J, it worked fine.
"Exception: oracle.oc4j.sql.config.DataSourceConfigException: Unable to create : com.mysql.jdbc.Driver"
when trying to run my application.
As of JDeveloper 11, a new default directory structure for user-specific content in JDeveloper for Windows is used. The default location for the system subdirectory is now %APPDATA%\JDeveloper\systemXX.XX.XX.XX, where:
- %APPDATA% is the Windows Application Data directory for the user (usually C:\Documents and Settings\<username>
\Application Data ) - XX.XX.XX.XX is a unique number of the product build, for example, system11.1.1.0.17.45.02
So, in my case, the MySQL JDBC JAR file (mysql-connector-java-3.1.12-bin.jar) should go into the directory:
C:\Documents and Settings\
Once I put it there, and restarted the embedded OC4J, it worked fine.
måndag, september 03, 2007
Combining Information
It exists countless articles & blog entries about ADF, however, I have found that quite often do they not exactly cover the exact topic that I am looking for, but, if I combine a few of them they can often together build a solution that is useful for me.
For example, in most cases when you want to display a certain record, the easiest approach if to use a ViewObject with a bind variable and then use the executeWithParams approach, as described in Duncan's blog here:
http://groundside.com/blog/DuncanMills.php?title=executewithparams_my_new_best_buddy&more=1&c=1&tb=1&pb=1
Last week I was assisting one of our partners in a project, and they wanted to display a certain record, but they did not want to use this approach. Instead they wanted to set the selected record based on a parameter sent to the page, and set the record is something like an 'onLoad' event for the page. So, what we did here was to use the processScope variable as described in this article to send the parameter:
http://www.oracle.com/technology/products/jdev/htdocs/partners/addins/exchange/jsf/doc/devguide/communicatingBetweenPages.html
and then combining this with an ADF Page Phase Listener as described here to set the record:
http://groundside.com/blog/DuncanMills.php?title=adf_executing_code_on_page_load&more=1&c=1&tb=1&pb=1
The PagePhaseListener is implemented in the backing bean and this then uses the setCurrentRowWithKeyValue to set the correct row in the iterator, something like:
if (event.getPhaseId() == Lifecycle.PREPARE_MODEL_ID) {
AdfFacesContext afContext = AdfFacesContext.getCurrentInstance();
String myValue = (String)afContext.getProcessScope().get("myKey");
FacesPageLifecycleContext ctx = (FacesPageLifecycleContext)event.getLifecycleContext();
DCIteratorBinding iter = ((DCBindingContainer)ctx.getBindingContainer()).findIteratorBinding("
DepartmentsView1Iterator");
iter.setCurrentRowWithKeyValue(myValue);
}
So, all-in-all, by combining 2 useful articles, I were able to solve the problem, even if no single article covered the problem.
For example, in most cases when you want to display a certain record, the easiest approach if to use a ViewObject with a bind variable and then use the executeWithParams approach, as described in Duncan's blog here:
http://groundside.com/blog/DuncanMills.php?title=executewithparams_my_new_best_buddy&more=1&c=1&tb=1&pb=1
Last week I was assisting one of our partners in a project, and they wanted to display a certain record, but they did not want to use this approach. Instead they wanted to set the selected record based on a parameter sent to the page, and set the record is something like an 'onLoad' event for the page. So, what we did here was to use the processScope variable as described in this article to send the parameter:
http://www.oracle.com/technology/products/jdev/htdocs/partners/addins/exchange/jsf/doc/devguide/communicatingBetweenPages.html
and then combining this with an ADF Page Phase Listener as described here to set the record:
http://groundside.com/blog/DuncanMills.php?title=adf_executing_code_on_page_load&more=1&c=1&tb=1&pb=1
The PagePhaseListener is implemented in the backing bean and this then uses the setCurrentRowWithKeyValue to set the correct row in the iterator, something like:
if (event.getPhaseId() == Lifecycle.PREPARE_MODEL_ID) {
AdfFacesContext afContext = AdfFacesContext.getCurrentInstance();
String myValue = (String)afContext.getProcessScope().get("myKey");
FacesPageLifecycleContext ctx = (FacesPageLifecycleContext)event.getLifecycleContext();
DCIteratorBinding iter = ((DCBindingContainer)ctx.getBindingContainer()).findIteratorBinding("
DepartmentsView1Iterator");
iter.setCurrentRowWithKeyValue(myValue);
}
So, all-in-all, by combining 2 useful articles, I were able to solve the problem, even if no single article covered the problem.
måndag, augusti 20, 2007
New Semester, New Job
fredag, juni 29, 2007
JDeveloper 10.1.3.3 Released
JDeveloper 10.1.3.3 build 4157 has now been released to OTN for download:
http://www.oracle.com/technology/software/products/jdev/htdocs/soft10133.html
A list of the bugs fixed in this release can be found at:
http://www.oracle.com/technology/products/jdev/htdocs/10.1.3.3/fixlist.htm
http://www.oracle.com/technology/software/products/jdev/htdocs/soft10133.html
A list of the bugs fixed in this release can be found at:
http://www.oracle.com/technology/products/jdev/htdocs/10.1.3.3/fixlist.htm
tisdag, juni 26, 2007
Altering the Show/Hide Text of a "detailStamp" Facet
Another question that is related to the one that I answered in my previous post is how you can alter the Show/Hide text in the <f:facet name="detailStamp">. The answer to this one is to use the <af:showDetail id="showDetail1"> component instead and set the attributes disclosedText and undisclosedText.
If you drag and drop a Master table with in-line details in a JSF page with JDeveloper, it will generate code like:
<f:facet name="detailStamp">
<af:table rows="#{bindings.DeptView1.rangeSize}"
emptyText="No rows yet." var="detailRow"
value="#{row.children}">
<af:column headerText="#{row.children[0].labels.Ename}"
sortable="false" sortProperty="Ename">
<af:outputText value="#{detailRow.Ename}"/>
</af:column>
<af:column headerText="#{row.children[0].labels.Job}"
sortable="false" sortProperty="Job">
<af:outputText value="#{detailRow.Job}"/>
</af:column>
</af:table>
</f:facet>
for the in-line table. Here you cannot change the generated Show/Hide text that ADF generates. See the image below (in Swedish):
 If you want to modify these, to something like:
If you want to modify these, to something like:

you need to use some code along the line of:
<af:column headerText="Test" sortable="false">
<af:showDetail id="showDetail1" disclosedText="Brown" undisclosedText="Charlie">
<af:table rows="#{bindings.DeptView1.rangeSize}"
emptyText="No rows yet." var="detailRow"
value="#{row.children}">
<af:column headerText="#{row.children[0].labels.Ename}"
sortable="false" sortProperty="Ename">
<af:outputText value="#{detailRow.Ename}"/>
</af:column>
<af:column headerText="#{row.children[0].labels.Job}"
sortable="false" sortProperty="Job">
<af:outputText value="#{detailRow.Job}"/>
</af:column>
</af:table>
</af:showDetail>
</af:column>
If you do not want to have any text at all, just set the attributes disclosedText="" and undisclosedText="".
If you drag and drop a Master table with in-line details in a JSF page with JDeveloper, it will generate code like:
<f:facet name="detailStamp">
<af:table rows="#{bindings.DeptView1.rangeSize}"
emptyText="No rows yet." var="detailRow"
value="#{row.children}">
<af:column headerText="#{row.children[0].labels.Ename}"
sortable="false" sortProperty="Ename">
<af:outputText value="#{detailRow.Ename}"/>
</af:column>
<af:column headerText="#{row.children[0].labels.Job}"
sortable="false" sortProperty="Job">
<af:outputText value="#{detailRow.Job}"/>
</af:column>
</af:table>
</f:facet>
for the in-line table. Here you cannot change the generated Show/Hide text that ADF generates. See the image below (in Swedish):
 If you want to modify these, to something like:
If you want to modify these, to something like:
you need to use some code along the line of:
<af:column headerText="Test" sortable="false">
<af:showDetail id="showDetail1" disclosedText="Brown" undisclosedText="Charlie">
<af:table rows="#{bindings.DeptView1.rangeSize}"
emptyText="No rows yet." var="detailRow"
value="#{row.children}">
<af:column headerText="#{row.children[0].labels.Ename}"
sortable="false" sortProperty="Ename">
<af:outputText value="#{detailRow.Ename}"/>
</af:column>
<af:column headerText="#{row.children[0].labels.Job}"
sortable="false" sortProperty="Job">
<af:outputText value="#{detailRow.Job}"/>
</af:column>
</af:table>
</af:showDetail>
</af:column>
If you do not want to have any text at all, just set the attributes disclosedText="" and undisclosedText="".
torsdag, juni 21, 2007
Hiding the Header for the Selection Facet
A question that I have seen on a few occasions is how you can hide the "Select" heading in the table when using the selection facet. Here is a solution for that problem that is based on this entry: http://www.orablogs.com/fnimphius/archives/001973.html in Frank Nimphius blog. Please note that, as Frank writes, that "Note that the CSS uses translateable text (or here translateable component names) to identify the component, which makes this solution weak.".
You can hide the 'Select' text by setting the text size to 0 for the concerned table header style (using display:none will not work, as it will cause the table headers to display over the incorrect column).
Here is the Table as default:
 The "Select" (or in Swedish "Välj") header is controlled by this style (th.x2z) element (see page source):
The "Select" (or in Swedish "Välj") header is controlled by this style (th.x2z) element (see page source):
<th scope="col" width="1%" nowrap class="x2z">Välj</th>
Now you can alter the af:tableSelectMany by changing the code in the page to:
<f:facet name="selection">
<af:tableSelectMany text="Test">
<f:verbatim>
<style type="text/css">
th.x2z{font-size: 0};
</style>
</f:verbatim>
</af:tableSelectMany>
</f:facet>
This will result in the following table:

Now the "Select" (or "Välj") test is set to 0 size, thus will not be displayed.
You can hide the 'Select' text by setting the text size to 0 for the concerned table header style (using display:none will not work, as it will cause the table headers to display over the incorrect column).
Here is the Table as default:
 The "Select" (or in Swedish "Välj") header is controlled by this style (th.x2z) element (see page source):
The "Select" (or in Swedish "Välj") header is controlled by this style (th.x2z) element (see page source): <th scope="col" width="1%" nowrap class="x2z">Välj</th>
Now you can alter the af:tableSelectMany by changing the code in the page to:
<f:facet name="selection">
<af:tableSelectMany text="Test">
<f:verbatim>
<style type="text/css">
th.x2z{font-size: 0};
</style>
</f:verbatim>
</af:tableSelectMany>
</f:facet>
This will result in the following table:

Now the "Select" (or "Välj") test is set to 0 size, thus will not be displayed.
torsdag, juni 14, 2007
Running a JAR File that Includes Another JAR From the Command Prompt
Today I got a question from a colleague on how-to run a JAR file that includes another JAR file directly from the command prompt, he couldn't get this to work - it just ended up with java.lang.NoClassDefFoundError exception. At first glance this seemed quite trivial, but it turned out to be more complicated than I first thought. My initial attempts also resulted in java.lang.NoClassDefFoundError, so I started to search around a bit for further information about the topic. This led me to this site http://one-jar.sourceforge.net/, and (as always) it turned out that someone else already solved the problem.
As I use JDeveloper (of course...) it needs to be added a few steps in addition to using one-jar to get the whole process to work, this is documented below.
1. First I created a new Workspace in JDeveloper with 2 projects 'mainproject' and 'subproject'.
2. In the 'subproject' there is a single dummy that have one method that just writes something to the System.out. There is also a JAR deployment profile that includes the mentioned class. The target JAR file I just called sub.jar.
3. Now it's time to create the 'mainproject'. As I am using the One-JAR in the end there are 2 restrictions I need to take into account for this project:
a. The main class needs to be named 'Main'
b. The target JAR file needs to be called 'main.jar'
I created a new class called 'Main' in the 'mainproject', added a dependency in the Project Properties to 'subproject' and created a dummy method in this class that uses the class created under 2. I ran the Main class inside JDeveloper to ensure that it worked before proceeding.
After that I created a JAR deployment profile. I made sure to name the target JAR file to 'main.jar'. Also checked the 'Include Manifest File (META-INF/MANIFEST.MF)' box and pointed the 'Main Class' to my 'Main' class. Next I made sure NOT to include my classes from the 'subproject' into this JAR file. This as they will be provided in a separate JAR file.
4. Next, it was time to download and install One-JAR. One-JAR can be downloaded from http://sourceforge.net/projects/one-jar. I created a new empty folder on my file system and placed the one-jar-boot-0.95.jar file there and renamed this to one-jar.jar. In my newly created folder I also added 2 subfolders 'main' and 'lib'. Once done I deployed my 2 JAR filed from JDeveloper, main.jar and sub.jar and placed them in the respective folders (main.jar in main and sub.jar in lib). The archive now has a structure similar to what is shown below:
As I use JDeveloper (of course...) it needs to be added a few steps in addition to using one-jar to get the whole process to work, this is documented below.
1. First I created a new Workspace in JDeveloper with 2 projects 'mainproject' and 'subproject'.
2. In the 'subproject' there is a single dummy that have one method that just writes something to the System.out. There is also a JAR deployment profile that includes the mentioned class. The target JAR file I just called sub.jar.
3. Now it's time to create the 'mainproject'. As I am using the One-JAR in the end there are 2 restrictions I need to take into account for this project:
a. The main class needs to be named 'Main'
b. The target JAR file needs to be called 'main.jar'
I created a new class called 'Main' in the 'mainproject', added a dependency in the Project Properties to 'subproject' and created a dummy method in this class that uses the class created under 2. I ran the Main class inside JDeveloper to ensure that it worked before proceeding.
After that I created a JAR deployment profile. I made sure to name the target JAR file to 'main.jar'. Also checked the 'Include Manifest File (META-INF/MANIFEST.MF)' box and pointed the 'Main Class' to my 'Main' class. Next I made sure NOT to include my classes from the 'subproject' into this JAR file. This as they will be provided in a separate JAR file.
4. Next, it was time to download and install One-JAR. One-JAR can be downloaded from http://sourceforge.net/projects/one-jar. I created a new empty folder on my file system and placed the one-jar-boot-0.95.jar file there and renamed this to one-jar.jar. In my newly created folder I also added 2 subfolders 'main' and 'lib'. Once done I deployed my 2 JAR filed from JDeveloper, main.jar and sub.jar and placed them in the respective folders (main.jar in main and sub.jar in lib). The archive now has a structure similar to what is shown below:

5. Now it's time to test this, and if it works correctly then the result should look something like:
D:\home\Demos\OneJARDemo\deploy>java -jar one-jar.jar
Hello from Main
Hello from sub project!
måndag, juni 04, 2007
About Rules and Execution Order
A question that pops-up from time to time is about Rules and execution order, i.e., is there a way to control the execution order of rules? There are technically two ways of doing this. The first way of obtaining this is by using rule priorities, the second is to use the ruleset stack.
However, I believe that using rule priorities in general should really be avoided, and is usually discouraged for two reasons; first, if will impact performance negative with respect to the built-in conflict resolution strategies. Secondly, it is considered bad style to use priorities in rule based programming to try to force a specific order. If you find yourself using priorities for most of your rules, then you should consider if using a rule based approach is really the best solution for your problem. If you want strict control over execution order, then you are really using procedural programming and not rule based programming.
If you still want to execution order, you should use the ruleset stack. This will be a more flexible solution than using a single ruleset and using rule priorities. How to do this is described in the Oracle Business Rules Language Reference, section 1.4.3 'Ordering Rule Firing'.
However, I believe that using rule priorities in general should really be avoided, and is usually discouraged for two reasons; first, if will impact performance negative with respect to the built-in conflict resolution strategies. Secondly, it is considered bad style to use priorities in rule based programming to try to force a specific order. If you find yourself using priorities for most of your rules, then you should consider if using a rule based approach is really the best solution for your problem. If you want strict control over execution order, then you are really using procedural programming and not rule based programming.
If you still want to execution order, you should use the ruleset stack. This will be a more flexible solution than using a single ruleset and using rule priorities. How to do this is described in the Oracle Business Rules Language Reference, section 1.4.3 'Ordering Rule Firing'.
onsdag, maj 30, 2007
ADF Faces Multi Select Table using JDeveloper 11g Technology Preview
About a year ago Frank Nimphius wrote this post (http://www.orablogs.com/fnimphius/archives/001778.html) about multi-selection in ADF Faces tables. I tried out this approach recently using the JDeveloper 11g Technology Preview release and found that things have changed slightly since then. The purpose here is not to fully describe this feature, for that please see Frank's post, but to point to the changes between 10.1.3 and the 11g Preview version.
These are the main changes in short:
Once you have created the table using 11g, you will notice that it looks slightly different:
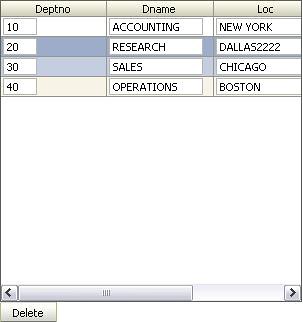
As mentioned before, you no longer needs to use a 'tableSelectMany' component to get multi-selections for the table, instead you define the 'rowSelection' and 'binding' attributes directly on the 'table' element, like:
<af:table value="#{bindings.DeptView1.collectionModel}" var="row"
rows="#{bindings.DeptView1.rangeSize}"
first="#{bindings.DeptView1.rangeStart}"
emptyText="#{bindings.DeptView1.viewable ? 'No rows yet.' : 'Access Denied.'}"
fetchSize="#{bindings.DeptView1.rangeSize}"
rowSelection="multiple" id="table1"
selectionListener="#{api.table1_selectionListener}"
binding="#{api.myTable}"
>
Next, you need to map the managed bean to use the RichTable class, like:
<managed-property>
property-name myTable /property-name
property-class oracle.adf.view.rich.component.rich.data.RichTable /property-class
value>#{table1} /value
/managed-property
private RichTable _table;
public RichTable getMyTable() {
return _table;
}
public void setMyTable(RichTable table) {
this._table = table;
}
As mentioned before, the way to iterate through the rows have also changed a bit. In 10.1.3 you could use:
Key _key = (Key) keyIter.next();
directly, in 11g I noticed that you have to use this approach instead:
List l = (List)rowSetIter.next();
Key key = (Key)l.get(0);
Also, you use the 'getSelectedRowKeys()' method instead of 'getSelectionState().getKeySet()'. The full code will look something like:
RichTable table = this.getMyTable();
RowKeySet rowSet = table.getSelectedRowKeys();
Iterator rowSetIter = rowSet.iterator();
DCBindingContainer bindings = this.getBindingContainer();
DCIteratorBinding iter = bindings.findIteratorBinding("DeptView1Iterator");
while (rowSetIter.hasNext()) {
List l = (List)rowSetIter.next();
Key key = (Key)l.get(0);
iter.setCurrentRowWithKey(key.toStringFormat(true));
Row r = iter.getCurrentRow();
System.out.println("selected dept " + r.getAttribute("Dname"));
}
Finally, with these changes in mind, the result of the above should end up in an output similar to:
07/05/30 13:36:33 selected dept SALES
07/05/30 13:36:33 selected dept RESEARCH
I hope this have illustrated the changes between the 10.1.3 and the 11g Preview Release for the multi-selection table.
These are the main changes in short:
- No need to create the selectMany component any longer.
- A Slightly different way to iterate through the rows is needed.
Once you have created the table using 11g, you will notice that it looks slightly different:
As mentioned before, you no longer needs to use a 'tableSelectMany' component to get multi-selections for the table, instead you define the 'rowSelection' and 'binding' attributes directly on the 'table' element, like:
<af:table value="#{bindings.DeptView1.collectionModel}" var="row"
rows="#{bindings.DeptView1.rangeSize}"
first="#{bindings.DeptView1.rangeStart}"
emptyText="#{bindings.DeptView1.viewable ? 'No rows yet.' : 'Access Denied.'}"
fetchSize="#{bindings.DeptView1.rangeSize}"
rowSelection="multiple" id="table1"
selectionListener="#{api.table1_selectionListener}"
binding="#{api.myTable}"
>
Next, you need to map the managed bean to use the RichTable class, like:
<managed-property>
private RichTable _table;
public RichTable getMyTable() {
return _table;
}
public void setMyTable(RichTable table) {
this._table = table;
}
As mentioned before, the way to iterate through the rows have also changed a bit. In 10.1.3 you could use:
Key _key = (Key) keyIter.next();
directly, in 11g I noticed that you have to use this approach instead:
List l = (List)rowSetIter.next();
Key key = (Key)l.get(0);
Also, you use the 'getSelectedRowKeys()' method instead of 'getSelectionState().getKeySet()'. The full code will look something like:
RichTable table = this.getMyTable();
RowKeySet rowSet = table.getSelectedRowKeys();
Iterator rowSetIter = rowSet.iterator();
DCBindingContainer bindings = this.getBindingContainer();
DCIteratorBinding iter = bindings.findIteratorBinding("DeptView1Iterator");
while (rowSetIter.hasNext()) {
List l = (List)rowSetIter.next();
Key key = (Key)l.get(0);
iter.setCurrentRowWithKey(key.toStringFormat(true));
Row r = iter.getCurrentRow();
System.out.println("selected dept " + r.getAttribute("Dname"));
}
Finally, with these changes in mind, the result of the above should end up in an output similar to:
07/05/30 13:36:33 selected dept SALES
07/05/30 13:36:33 selected dept RESEARCH
I hope this have illustrated the changes between the 10.1.3 and the 11g Preview Release for the multi-selection table.
tisdag, maj 08, 2007
New Technology Preview Releases of JDeveloper, OC4J & TopLink
The 11.1.1 Technology Preview releases of JDeveloper, OC4J and TopLink are now available for download on OTN. You can find them at these URL's:
JDeveloper:
http://www.oracle.com/technology/products/jdev/11/index.html
TopLink:
http://www.oracle.com/technology/software/products/ias/htdocs/1111topsoft.html
OC4J:
http://www.oracle.com/technology/software/products/ias/htdocs/utilsoft_preview.html
JDeveloper:
http://www.oracle.com/technology/products/jdev/11/index.html
TopLink:
http://www.oracle.com/technology/software/products/ias/htdocs/1111topsoft.html
OC4J:
http://www.oracle.com/technology/software/products/ias/htdocs/utilsoft_preview.html
fredag, april 27, 2007
Problems Calling .Net Web Services from UTL_DBWS
I've been having some issues with a problem from a customer, the scenario is quite simple; they simply want to call a .Net Web Service from the database using utl_dbws. This should be fairly straightforward, however, this did not work as expected, instead I've been keep getting this error message:
ORA-29532: Java call terminated by uncaught Java exception:
javax.xml.rpc.soap.SOAPFaultException: Server did not recognize the value of HTTP Header SOAPAction: .
ORA-06512: at "SYS.UTL_DBWS", line 387
ORA-06512: at "SYS.UTL_DBWS", line 384
and I could simply not figure out why. So, when I read the utl_dbws api for the 111:th time (give or take a few times...) I found that:
"'SOAPACTION_USE': This boolean property indicates whether or not SOAPAction is to be used. The default value of this property is 'FALSE'."
which certainly corresponds to the error message I've been getting, as it indicates that no SOAPAction is being sent.
So, I simply added these lines:
sys.utl_dbws.set_property(call_, 'SOAPACTION_USE', 'TRUE');
sys.utl_dbws.set_property(call_, 'SOAPACTION_URI', 'http://tempuri.org/Hello');
and the request went fine. A few lines that made the difference but took me too long time to find out...
The utl_dbws package is described in:
http://download-uk.oracle.com/docs/cd/B19306_01/appdev.102/b14258/u_dbws.htm#sthref13863
The The SOAPAction HTTP Header Field is described in:
http://www.w3.org/TR/2000/NOTE-SOAP-20000508/#_Toc478383528
ORA-29532: Java call terminated by uncaught Java exception:
javax.xml.rpc.soap.SOAPFaultException: Server did not recognize the value of HTTP Header SOAPAction: .
ORA-06512: at "SYS.UTL_DBWS", line 387
ORA-06512: at "SYS.UTL_DBWS", line 384
and I could simply not figure out why. So, when I read the utl_dbws api for the 111:th time (give or take a few times...) I found that:
"'SOAPACTION_USE': This boolean property indicates whether or not SOAPAction is to be used. The default value of this property is 'FALSE'."
which certainly corresponds to the error message I've been getting, as it indicates that no SOAPAction is being sent.
So, I simply added these lines:
sys.utl_dbws.set_property(call_, 'SOAPACTION_USE', 'TRUE');
sys.utl_dbws.set_property(call_, 'SOAPACTION_URI', 'http://tempuri.org/Hello');
and the request went fine. A few lines that made the difference but took me too long time to find out...
The utl_dbws package is described in:
http://download-uk.oracle.com/docs/cd/B19306_01/appdev.102/b14258/u_dbws.htm#sthref13863
The The SOAPAction HTTP Header Field is described in:
http://www.w3.org/TR/2000/NOTE-SOAP-20000508/#_Toc478383528
måndag, mars 19, 2007
Exposing a Java Service Facade for an EJB 3.0 Entity as a Web Service
A few days ago I tried to expose a Java Service Facade for an EJB 3.0 entity as a Web Service using JDeveloper. At first, I had a problem with this, however, once I found the culprit, it was quite obvious. Here are the steps I took:
2007-03-07 13:46:35.434 ERROR OWS-04046 Caught exception while handling request:
java.lang.NullPointerException java.lang.NullPointerException
So, what was the problem? This problem occurs when the persistance.xml file point to a datasource rather than a direct JDBC connection. Since the JavaServiceFacade class is plain J2SE class, using a datasource in the persistance.xml can be used with EJB application only. For example you can create a EJB SessionFacade and publish this as a Web Service. Once I had re-defined the persistance.xml to point to a direct JDBC connection, it worked, like:
...
<persistence-unit name="WebServicesMetaData">
<class>webservicesmetadata.Countries</class>
<properties>
<property name="toplink.jdbc.driver" value="oracle.jdbc.OracleDriver"/>
<property name="toplink.jdbc.url"
value="jdbc:oracle:thin:@myHost:myPort:mySID"/>
<property name="toplink.jdbc.user" value="hr"/>
<property name="toplink.jdbc.password" value="hr_password"/>
<property name="toplink.target-database" value="Oracle"/>
<property name="toplink.logging.level" value="FINER"/>
</properties>
</persistence-unit>
...
- Created Entity Objects - by using the Wizards in JDeveloper, this went very smooth.
- Created the JavaServiceFacade Exposing the Entity, no problems here either.
- Expose the Java Service Facade as a Web Service using the Wizards. So far so good.
- Configure the persistence.xml file.
2007-03-07 13:46:35.434 ERROR OWS-04046 Caught exception while handling request:
java.lang.NullPointerException java.lang.NullPointerException
So, what was the problem? This problem occurs when the persistance.xml file point to a datasource rather than a direct JDBC connection. Since the JavaServiceFacade class is plain J2SE class, using a datasource in the persistance.xml can be used with EJB application only. For example you can create a EJB SessionFacade and publish this as a Web Service. Once I had re-defined the persistance.xml to point to a direct JDBC connection, it worked, like:
...
<persistence-unit name="WebServicesMetaData">
<class>webservicesmetadata.Countries</class>
<properties>
<property name="toplink.jdbc.driver" value="oracle.jdbc.OracleDriver"/>
<property name="toplink.jdbc.url"
value="jdbc:oracle:thin:@myHost:myPort:mySID"/>
<property name="toplink.jdbc.user" value="hr"/>
<property name="toplink.jdbc.password" value="hr_password"/>
<property name="toplink.target-database" value="Oracle"/>
<property name="toplink.logging.level" value="FINER"/>
</properties>
</persistence-unit>
...
onsdag, februari 28, 2007
Recursion in Rules
Long time since I wrote something about Rules, so, here is a small sample for using recursion in Rules. Implementing recursion in Rules is fairly easy, just assert a new fact in the action-block of a rule, that's it. By asserting a new fact to the system, the system will re-evaluate, and recursion has taken place.
Below is an example that will illustrate this, it will find and print all ancestor relationships that are the result of three parent relationships. Andy is a parent of Betty, Betty is a parent of Charlie and Charlie is a parent of Donna. Which are the resulting ancestor relationships?
Running this program will reveal the result...
ruleset main {
class Parent {
String a;
String b;
}
class Ancestor {
String a;
String b;
}
// Convert a Parent relationship to an Ancestor relationship
rule parentToAncestor {
if ( (fact Parent p) ) {
assert(new Ancestor(a: p.a, b: p.b));
}
}
// If A is parent of B and B is an Ancestor of C, then A is an Ancestor of C
rule parentAndAncestorToAncestor {
if (
(fact Parent p) &&
(fact Ancestor a) &&
p.b.equals(a.a)
) {
assert(new Ancestor(a: p.a , b: a.b));
}
}
// Printout all Ancestors relationships
rule printAncestors {
if (fact Ancestor a) {
println(a.a + " is an ancestor of " + a.b);
}
}
// Setup some parent relations...
{
assert(new Parent(a: "Andy" , b: "Betty"));
assert(new Parent(a: "Betty" , b: "Charlie"));
assert(new Parent(a: "Charlie", b: "Donna"));
}
// Evaluate the ruleset
run();
}
below is the result:
Andy is an ancestor of Donna
Betty is an ancestor of Donna
Charlie is an ancestor of Donna
Andy is an ancestor of Charlie
Betty is an ancestor of Charlie
Andy is an ancestor of Betty
Below is an example that will illustrate this, it will find and print all ancestor relationships that are the result of three parent relationships. Andy is a parent of Betty, Betty is a parent of Charlie and Charlie is a parent of Donna. Which are the resulting ancestor relationships?
Running this program will reveal the result...
ruleset main {
class Parent {
String a;
String b;
}
class Ancestor {
String a;
String b;
}
// Convert a Parent relationship to an Ancestor relationship
rule parentToAncestor {
if ( (fact Parent p) ) {
assert(new Ancestor(a: p.a, b: p.b));
}
}
// If A is parent of B and B is an Ancestor of C, then A is an Ancestor of C
rule parentAndAncestorToAncestor {
if (
(fact Parent p) &&
(fact Ancestor a) &&
p.b.equals(a.a)
) {
assert(new Ancestor(a: p.a , b: a.b));
}
}
// Printout all Ancestors relationships
rule printAncestors {
if (fact Ancestor a) {
println(a.a + " is an ancestor of " + a.b);
}
}
// Setup some parent relations...
{
assert(new Parent(a: "Andy" , b: "Betty"));
assert(new Parent(a: "Betty" , b: "Charlie"));
assert(new Parent(a: "Charlie", b: "Donna"));
}
// Evaluate the ruleset
run();
}
below is the result:
Andy is an ancestor of Donna
Betty is an ancestor of Donna
Charlie is an ancestor of Donna
Andy is an ancestor of Charlie
Betty is an ancestor of Charlie
Andy is an ancestor of Betty
fredag, februari 23, 2007
Using the JDeveloper HTTP Analyser to Trace Web Services Calls from the RDBMS
As you know, you can use the HTTP Analyser within JDeveloper to examine the network traffic of a client connecting to a Web Service. Usually one uses the HTTP Analyser from within JDeveloper, but it can also be used to track calls from a Web Services client residing within the RDBMS.
This is the approach to take to do this:
First, you start the HTTP Analyser normally by selecting View Http Analyser within JDeveloper. It then opens in its own window inside JDeveloper, run the HTTP Analyser by clicking > '(the small green button...)'.
Next, you need to tell the RDBMS Web Service client to use this instance of the HTTP Analyser as a proxy, this can be done with the following line:
sys.utl_dbws.set_http_proxy('<host>:<port>');
and here you specify the host where JDeveloper is running as the host, the port is by default 8099, so unless you know that this has been changed, use this.
Now it's time to run the call to the Web Service. The request/response packet pairs will now be listed in the HTTP Analyser. To examine the content of a request/response pair highlight it in the History tab and then click the Data tab.
The should give you further details about the exact request / response sequence taking place.
This is the approach to take to do this:
First, you start the HTTP Analyser normally by selecting View Http Analyser within JDeveloper. It then opens in its own window inside JDeveloper, run the HTTP Analyser by clicking > '(the small green button...)'.
Next, you need to tell the RDBMS Web Service client to use this instance of the HTTP Analyser as a proxy, this can be done with the following line:
sys.utl_dbws.set_http_proxy('<host>:<port>
and here you specify the host where JDeveloper is running as the host, the port is by default 8099, so unless you know that this has been changed, use this.
Now it's time to run the call to the Web Service. The request/response packet pairs will now be listed in the HTTP Analyser. To examine the content of a request/response pair highlight it in the History tab and then click the Data tab.
The should give you further details about the exact request / response sequence taking place.
fredag, februari 16, 2007
Changed the Connection for a JDeveloper Generated PL/SQL Web Service
Have you ever been annoyed that the JDeveloper PL/SQL Wizard is not able to change the Connection? Once you have created the Web Service, the field for the Connection is not editable. At least I have.
Unfortunately doesn't the Wizard support switching the Connection. However, it is possible to do this in another way, this has not been tested to 100%, but I have used on several occasions and it seems to do the trick. So, if you want a 100% safe solution, you should re-create the Web Services. If you do not want to do that, and want to test this approach, you should ensure to have a backup of your project before progressing. Here is how you do it:
1. Close the JDeveloper project.
2. Open the file myProject\src\mypackage\MyWebService.jaxrpc
3. Edit the entry:
and change that to your new Connection and save the file.
4. Open the Project
5. Double click on the Web Service to open the Wizard. The new connection should now appear in the dialog. Click OK, this will re-generate the service to work towards the new connection.
Unfortunately doesn't the Wizard support switching the Connection. However, it is possible to do this in another way, this has not been tested to 100%, but I have used on several occasions and it seems to do the trick. So, if you want a 100% safe solution, you should re-create the Web Services. If you do not want to do that, and want to test this approach, you should ensure to have a backup of your project before progressing. Here is how you do it:
1. Close the JDeveloper project.
2. Open the file myProject\src\mypackage\MyWebService.jaxrpc
3. Edit the entry:
and change that to your new Connection and save the file.
4. Open the Project
5. Double click on the Web Service to open the Wizard. The new connection should now appear in the dialog. Click OK, this will re-generate the service to work towards the new connection.
torsdag, februari 01, 2007
Strange ADF Problem, Timepart of a Date Lost
Today I have been working on an issue that has intrigued me for a while. One of our customer has an application (ADF BC - Struts w. JSP) that first inserts some data into an Oracle DB by creating a new row in the corresponding ViewObject, then fetches some additional data from another DB, and updates the newly created ViewObject with this data, however, this process has failed. While debugging this problem I noticed that one of the parts of the Primary Key was a Date column, and in the log files there were entries like:
oracle.jbo.RowAlreadyDeletedException: JBO-25019: Riga entit? della chiave oracle.jbo.Key[1 2006-12-27 aaa] non trovata in MyTable.
I also noticed the following a bit further down in the log:
06/12/27 12:22:31 [515] Original value :2006-12-27 12:22:28.0
06/12/27 12:22:31 [516] Target value :2006-12-27
so, it seems quite obvious why the error occurs, the only question now would be why. Now, I wanted to have the error messages in English, so I then added -Duser.lang=en_US, and restarted the Application. Obviously I expected to get the error messages in English, but instead, it worked fine. Strange... I hope to find some explanation for this...
oracle.jbo.RowAlreadyDeletedException: JBO-25019: Riga entit? della chiave oracle.jbo.Key[1 2006-12-27 aaa] non trovata in MyTable.
I also noticed the following a bit further down in the log:
06/12/27 12:22:31 [515] Original value :2006-12-27 12:22:28.0
06/12/27 12:22:31 [516] Target value :2006-12-27
so, it seems quite obvious why the error occurs, the only question now would be why. Now, I wanted to have the error messages in English, so I then added -Duser.lang=en_US, and restarted the Application. Obviously I expected to get the error messages in English, but instead, it worked fine. Strange... I hope to find some explanation for this...
fredag, januari 12, 2007
Fix for Bug ADF JClient bug 5642176 Available
In the OTN thread:
http://forums.oracle.com/forums/thread.jspa?threadID=297913&start=15&tstart=0
there is a discusssion about a problem related to the ADF JClient bug 5642176. The patch for this bug is now available for download on MetaLink. To download it:
1) In MetaLink, click tab "Patches & Updates"
2) Click "Simple Search"
3) Select "Search By" "Patch Number"
4) Enter the patch number: 5642176
5) Select Microsoft Win-32 bit as the Platform (the patch is still Generic)
6) Click "Go"
7) Click "View Readme" and follow instructions to install the patch.
The patch is available for JDeveloper 10.1.2.2 and 10.1.3.1. Please also refer to the MetaLink Note 406050.1 for further details.
http://forums.oracle.com/forums/thread.jspa?threadID=297913&start=15&tstart=0
there is a discusssion about a problem related to the ADF JClient bug 5642176. The patch for this bug is now available for download on MetaLink. To download it:
1) In MetaLink, click tab "Patches & Updates"
2) Click "Simple Search"
3) Select "Search By" "Patch Number"
4) Enter the patch number: 5642176
5) Select Microsoft Win-32 bit as the Platform (the patch is still Generic)
6) Click "Go"
7) Click "View Readme" and follow instructions to install the patch.
The patch is available for JDeveloper 10.1.2.2 and 10.1.3.1. Please also refer to the MetaLink Note 406050.1 for further details.
Prenumerera på:
Inlägg (Atom)
